|
|
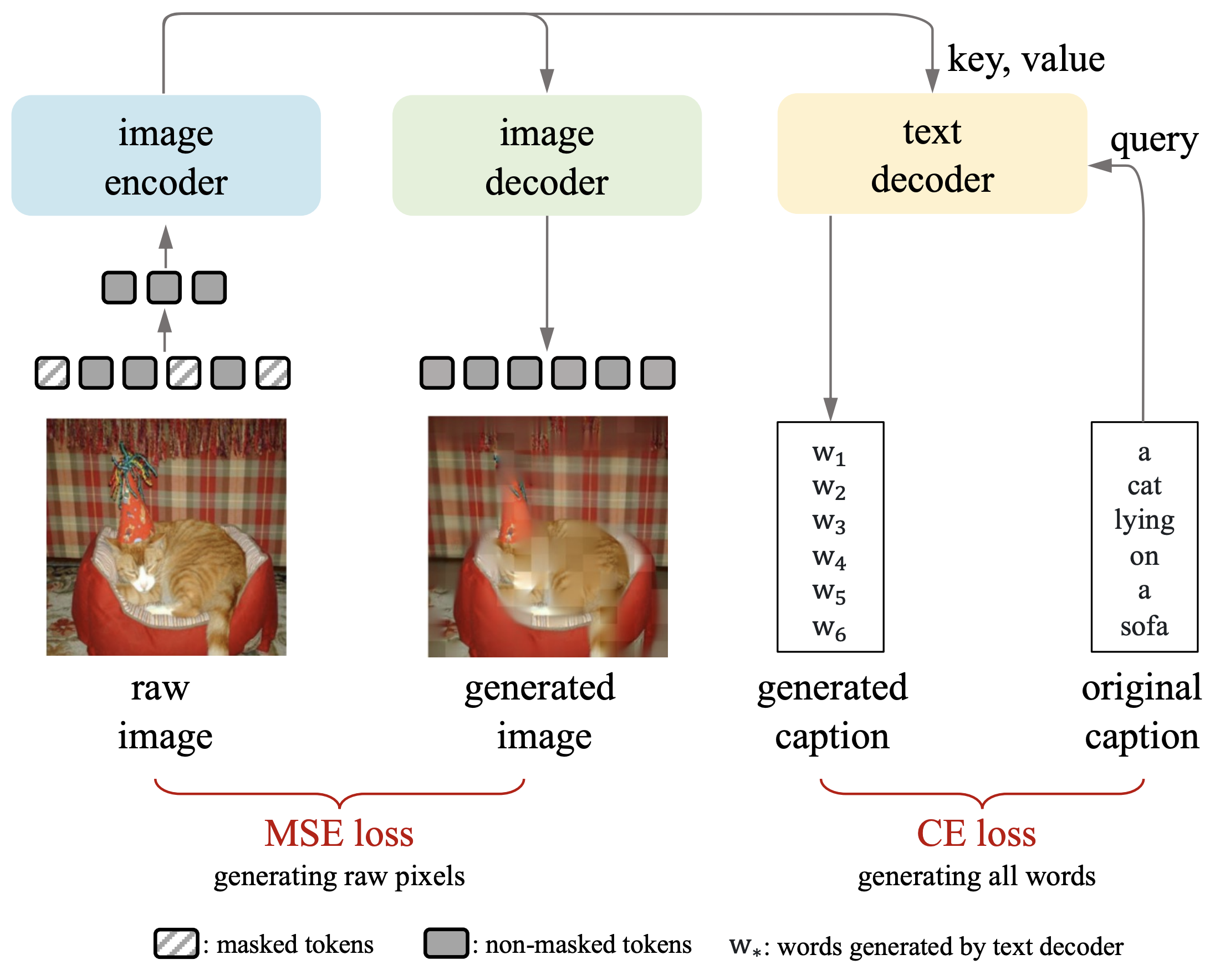
Illustration of Our method: MUG.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Illustration of Our method: MUG.
|
| Most recent self-supervised learning~(SSL) methods are pre-trained on the well-curated ImageNet-1K dataset. In this work, we consider SSL pre-training on noisy web image-text paired data due to the excellent scalability of web data. First, we conduct a benchmark study of representative SSL pre-training methods on large-scale web data in a fair condition. Methods include single-modal ones such as MAE and multi-modal ones such as CLIP. We observe that multi-modal methods cannot outperform single-modal ones on vision transfer learning tasks. We derive an information-theoretical view to explain the benchmarking results, which provides insights into designing novel vision learners. Inspired by the above explorations, we present a visual representation pre-training method, MUlti-modal Generator~(MUG), for scalable web image-text data. MUG achieves state-of-the-art transferring performances on a variety of tasks and shows promising scaling behavior. |
| To understand what pretraining paradigm performs the best in terms of transfer learning, we conduct a benchmark study on a large-scale web image-text dataset: CC3M. We compare the performance of single-modal and multi-modal vision learners on the ability to learn transferrable representations by evaluating the representation on ImageNet-1k image classification task. |
|
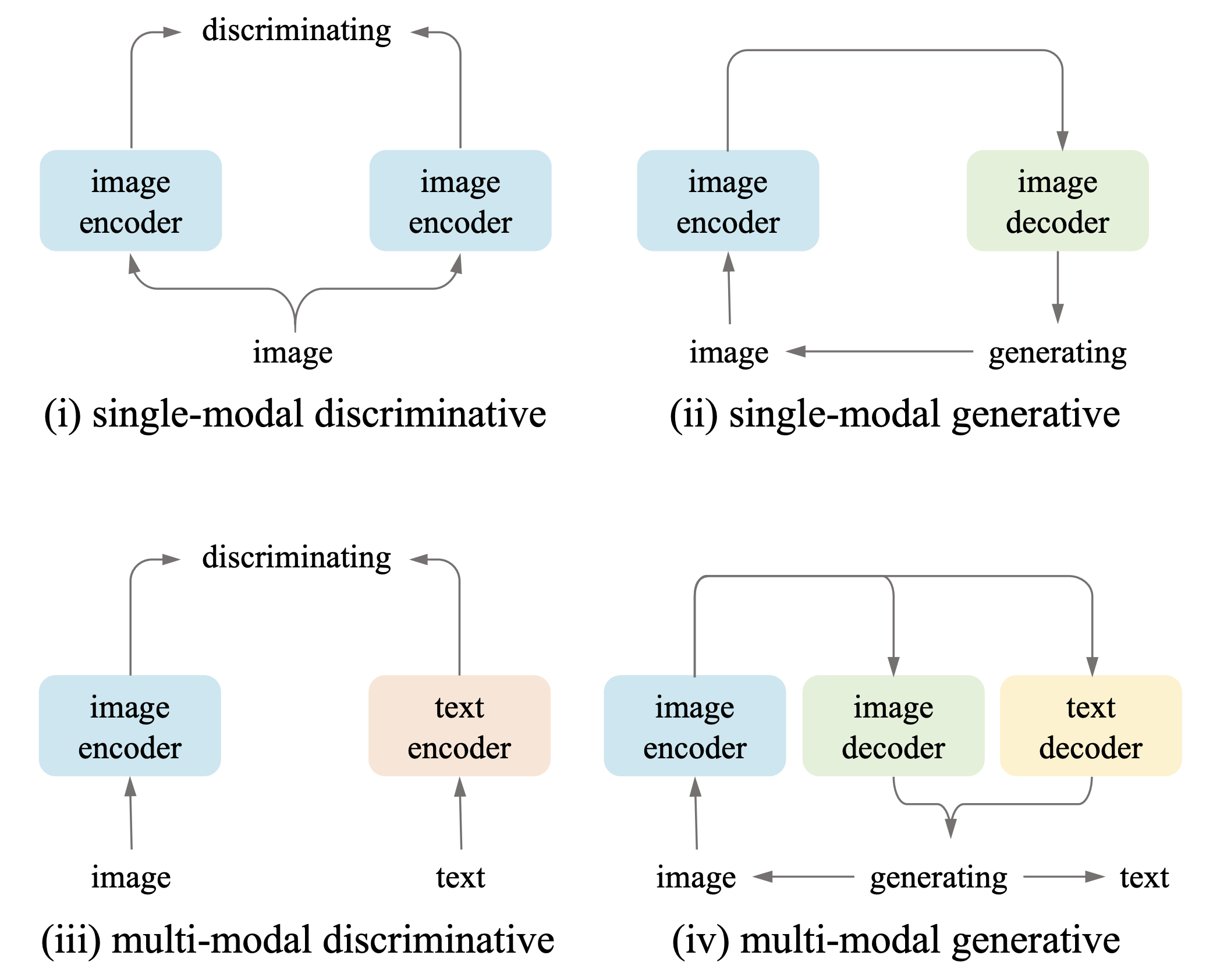
|
Comparison of vision encoder pre-training paradigms with image-text pairs. Four paradigms
are considered, i.e., (i) single-modal discriminative (e.g., SimCLR), (ii)
single-modal generative (e.g., MAE), (iii) multi-modal discriminative (e.g.,
CLIP), and (iv) multi-modal generative (our proposed MUG). Multi-modal generative paradigm
simultaneously generates images and texts with only image representations.
|
|
|
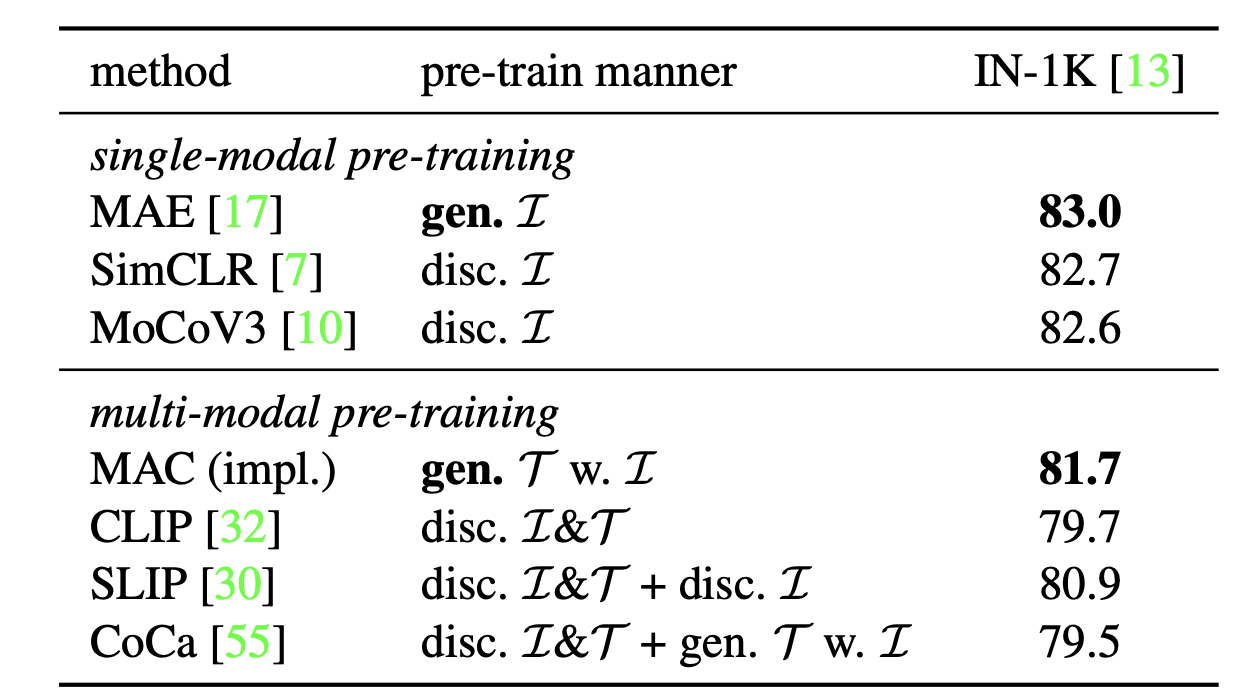
Comparison of previous pre-training methods. All models are pre-trained on the CC3M, and
evaluated on ImageNet-1K (IN-1K) via end-to-end fine-tuning. "gen. and dist." are short for
generating and discriminating. "
and
" denote images and texts. For instance, SimCLR is
pre-trained by discriminating images (disc.
). CLIP is pre-trained by discriminating image-text
pairs (disc.
&
). CoCa has two objectives: discriminating
image-text pairs (disc.
&
) and generating texts with images (gen.
w.
). Other than existing methods, we implement (impl.)
a MAsked Captioner (MAC) to generate texts with masked image patches (gen.
w.
).
Key Observations: 1) Generative methods (e.g., MAE) achieve the best results. 2) Present multi-modal methods cannot outperform single-modal ones. |

We provide an information-theoretical view on these two observations, the basic idea is that generative pretraining can help the network maintain a larger bottleneck which is beneficial for transfer learning, for more discussions, please refer to the main paper and also this paper on discriminability-transferability trade-off. |
MUlti-modal Generator (MUG) for learning visual representations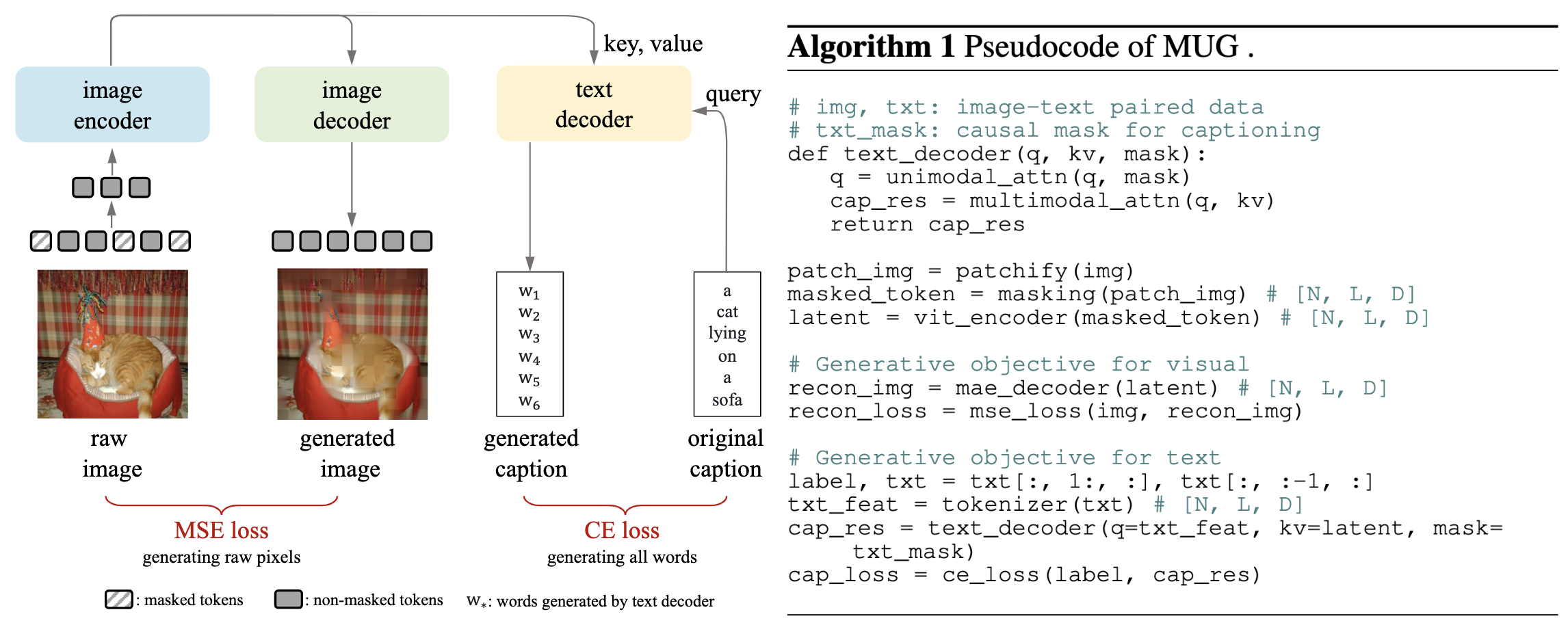
|
|
llustration and the pseudo-code of MUG. The input image is masked and fed into the image encoder, and then the resulting latent representation will be used by an image decoder and a text decoder. The image decoder enables the training objective of generative the raw pixels of the image, and the text decoder enables the training objective of generating the paired caption of the input image. |
Experiment results |
|
Comparison of pre-training methods on ImageNet-1K (IN-1K) fine-tuning, and top-1
accuracies are
reported. Besides, we evaluated fine-tuned models on ImageNet-Adversarial (IN-A) and
ImageNet-Rendition (IN-R) for evaluating out-of-distribution performances.
means the
model is pre-trained with our collected 200M web image-text pairs.
is pre-trained on IN-1K.
|
|
|
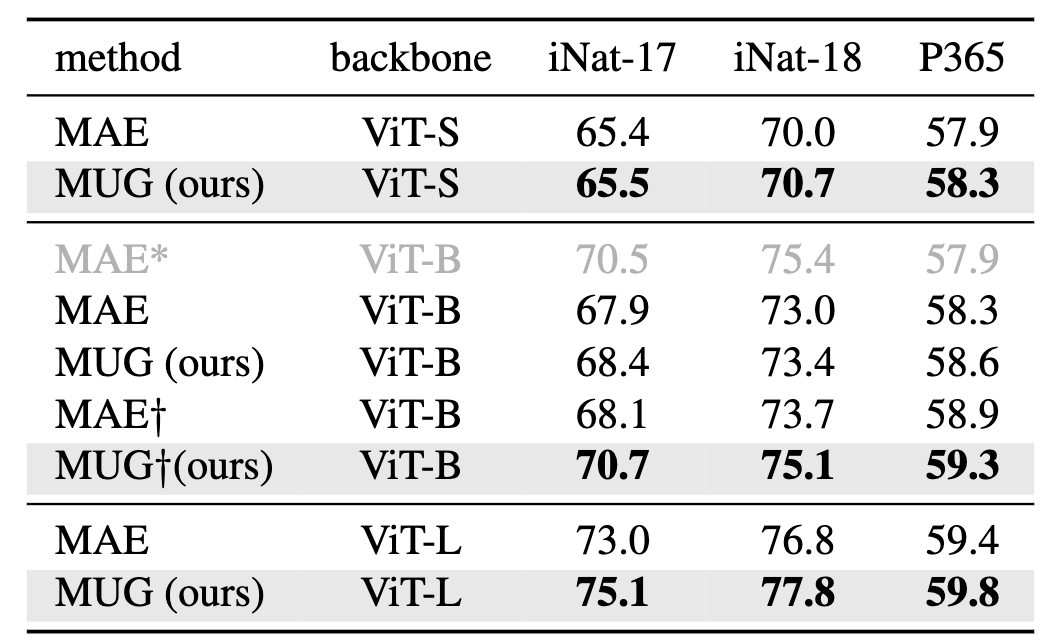
Comparison of pre-training methods on fine-grained dataset iNatualist-17 (iNat-17),
iNaturalist-18 (iNat-18), and Places365 (P365) fine-tuning. Top-1 accuracies are reported.
means the model is pre-trained with our collected 200M
web image-text pairs.
|
|
|
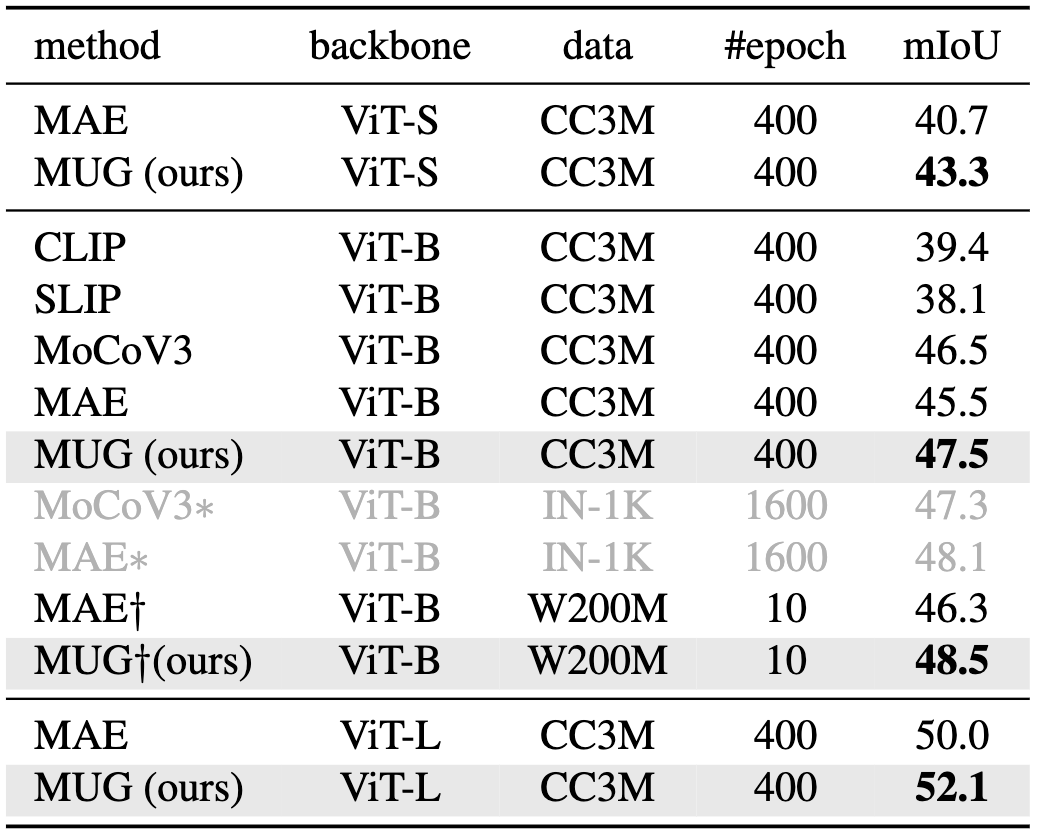
Comparison of pre-training methods on ADE20K dataset semantic segmentation fine-tuning,
mIoU scores are reported.
|
Visualization results
|
| Reconstruction of masked images and captions on the MS-COCO (upper) and PASCAL-VOC (bottom) datasets. |
@article{zhao23mug,
author = {Bingchen Zhao and Quan Cui and Hao Wu and Osamu Yoshie and Cheng Yang and Oisin Mac Aodha},
title = {Vision Learners Meet Web Image-Text Pairs},
journal = {arXiv preprint arXiv:2301.07088},
year = {2023}
}
|
|
|
|