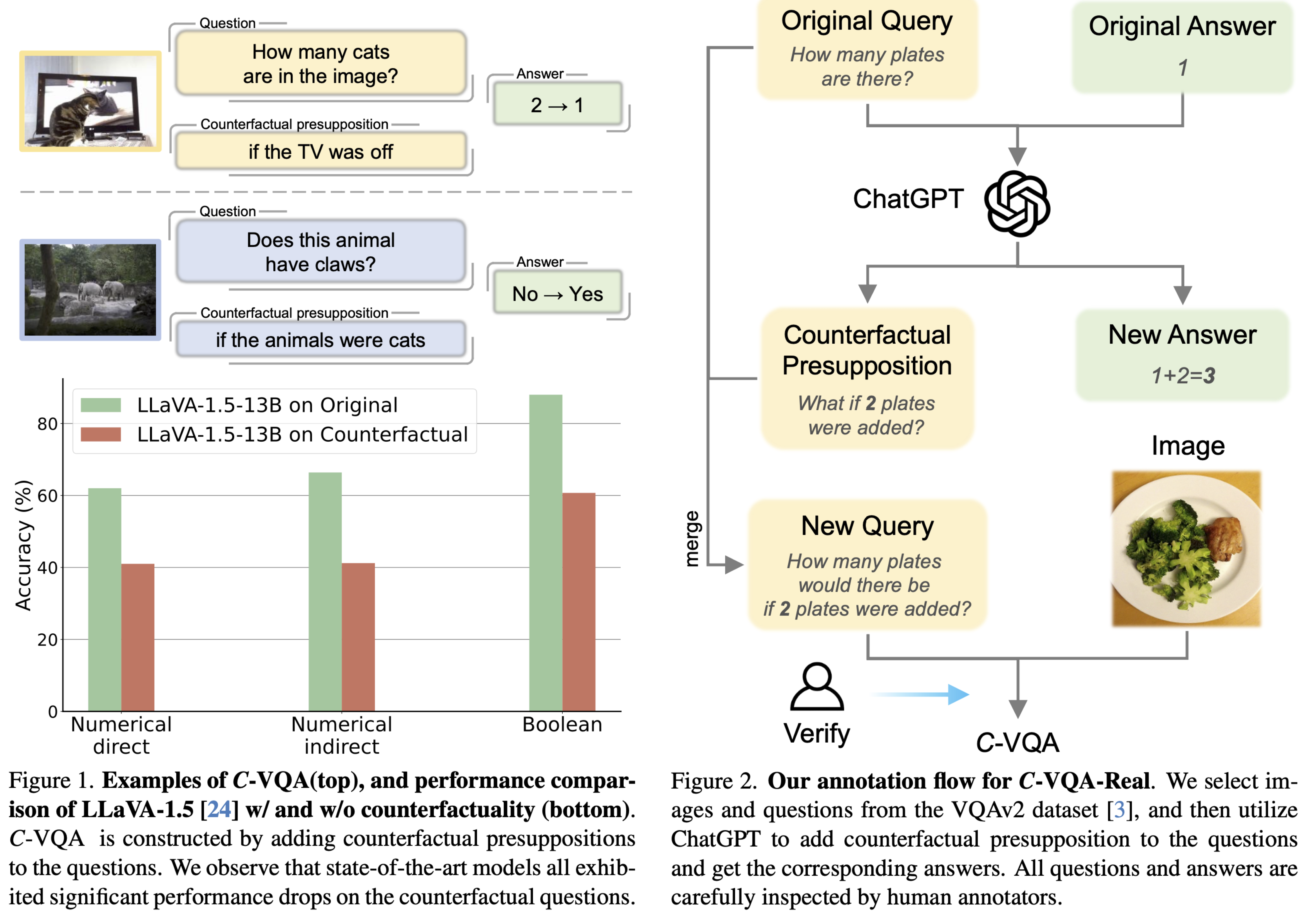
Counterfactual reasoning, a fundamental aspect of human cognition, involves contemplating alternatives to established facts or past events, significantly enhancing our abilities in planning and decision-making. In light of the advancements in current multi-modal large language models, we explore their effectiveness in counterfactual reasoning. To facilitate this investigation, we introduce a novel dataset, C-VQA, specifically designed to test the counterfactual reasoning capabilities of modern multi-modal large language models. This dataset is constructed by infusing original questions with counterfactual presuppositions, spanning various types such as numerical and boolean queries. It encompasses a mix of real and synthetic data, representing a wide range of difficulty levels. Our thorough evaluations of contemporary vision-language models using this dataset have revealed substantial performance drops, with some models showing up to a 40% decrease, highlighting a significant gap between current models and human-like vision reasoning capabilities. We hope our dataset will serve as a vital benchmark for evaluating the counterfactual reasoning capabilities of models.
@article{zhang2023cvqa,
author = {Zhang, Letian and Zhai, Xiaotong and Zhao, Zhongkai and Zong, Yongshuo and Wen, Xin and Zhao, Bingchen},
title = {What If the TV Was Off? Examining Counterfactual Reasoning Abilities of Multi-modal Language Models},
journal = {arXiv:2310.06627},
year = {2023}
}|
|